
KonText
KonText is a basic web application for querying corpora available within the LINDAT/CLARIAH-CZ project. It allows evaluation of simple and complex queries, displaying their results as concordance lines, computing frequency distribution, calculating association measures for collocations and further work with language data. This LINDAT/CLARIAH-CZ instance is a fork of KonText application developed by the Institute of the Czech National Corpus that has been further extended by the Institute of Formal and Applied Linguistics to suit the needs of LINDAT/CLARIAH-CZ project.
There is a general guide on how to search corpora in KonText below. More examples for the particular corpora are available: CWC, HamleDT 3.0, PARSEME MWE, PDT, UD, and other corpora
How to search in a corpus
1. After selecting a corpus at http://lindat.mff.cuni.cz/services/kontext/run.cgi/corplist, you can switch to the other by clicking the corpus name Corpus:
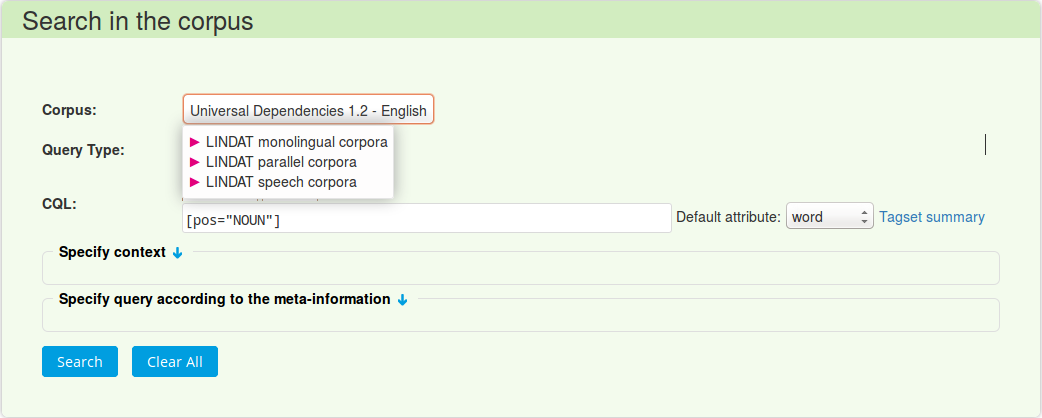
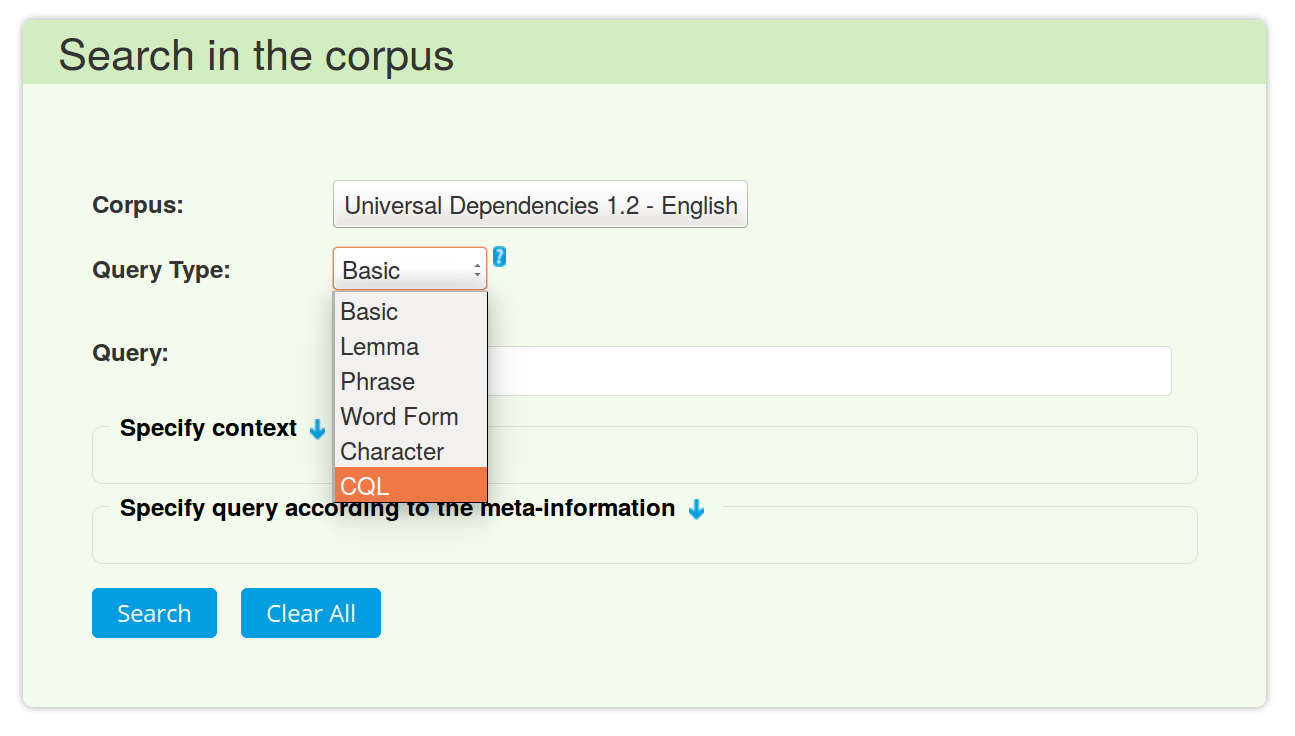
2. Select the Query Type. To search for words/word sequences, use Basic. For more sophisticated linguistic queries choose CQL (manual on CQL https://www.sketchengine.co.uk/corpus-querying/#CorpusQueryLanguageCQL)
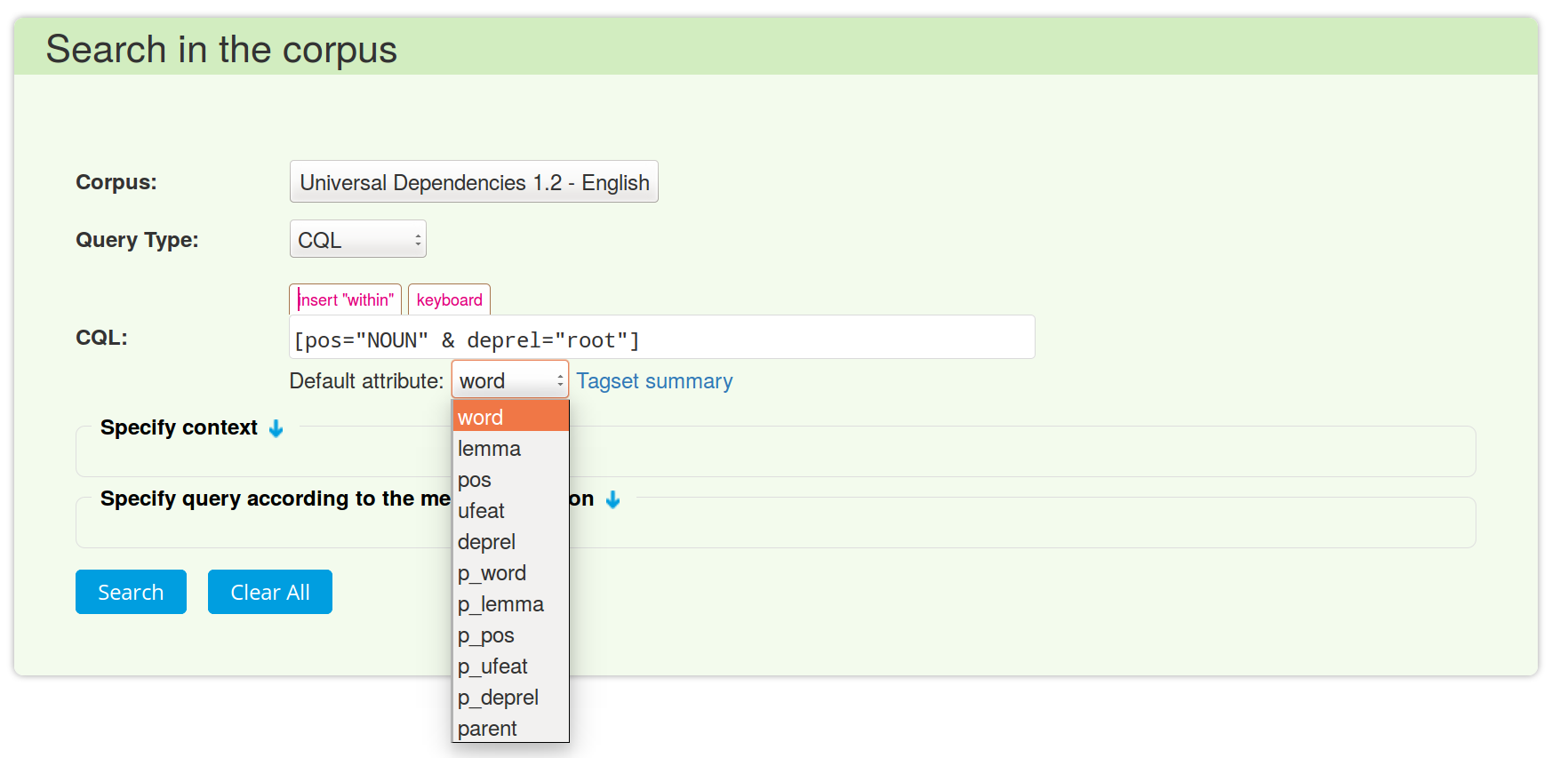
3. Click on Default attribute to see the list of attributes. You do not have to switch the attribute if you want to use more of them in your query
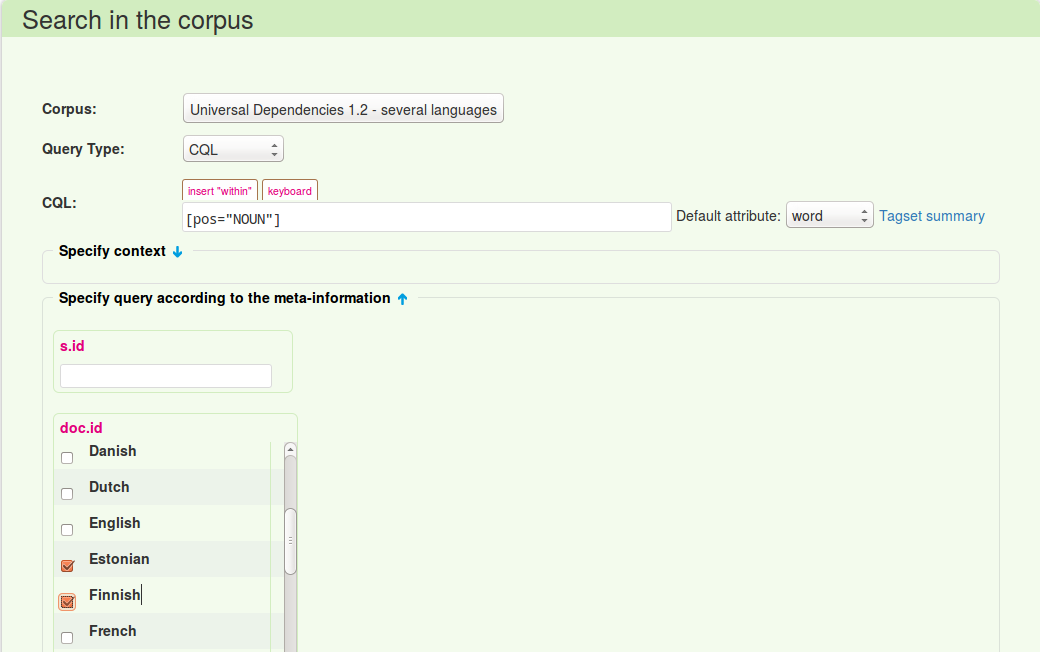
4. In order to execute meta-information query (like document or sentence id, etc - the meta-information is unique for each of Lindat corpora), select Specify query according to the meta-information
Further detailed information on KonText search in English and Czech can be found here: https://wiki.korpus.cz/doku.php/en:manualy:kontext:index. The description is given for another set of corpora not present in LINDAT/CLARIAH-CZ, so specific corpora information may be different.