
Frequently Asked Questions on LINDAT/CLARIAH-CZ Repository
Repository
- What is the LINDAT/CLARIAH-CZ repository?
- Why should I submit my data into your repository?
- Why should I submit my tools?
- Do I need to create an account to download and/or make a submission?
- How to sign up?
- I see an error logging in
- What submissions do you accept?
- Why do you strongly prefer real authors to institutions?
Deposit and Update
- What is the deposited item lifecycle?
- What is the actual depositing/archiving procedure?
- How safe is my data if I store it with you?
- What is the PID (handle) good for?
- How do I create a new version of a record?
- How do I update the submitted data?
- What if I want/need to update the archived data?
- What if I want to withdraw the resources in the future? Can I delete the data?
- I don't want / cannot make the data publicly available or make them available after a specific date. Would you still archive them for me?
- We have started our own repository, can we somehow move records submitted to the LRT collection?
License
- What license should I pick for my data/tool?
- Where can I find more information about supported licenses?
Citation
What is the LINDAT/CLARIAH-CZ repository?
A repository is like a library for linguistic data and tools. Users can
- search for data and tools and easily download them.
- deposit the data and be sure it is safely stored, everyone can find it, use it, and correctly cite it (giving you credit)
The LINDAT/CLARIAH-CZ repository is hosted at Institute of Formal and Applied Linguistics, Charles University (UFAL).
Mission Statement
The ultimate objective of CLARIN ERIC (which LINDAT/CLARIAH-CZ is part of) is to advance research in humanities and social sciences by giving researchers unified single sign-on access to a platform which integrates language-based resources and advanced tools at a European level. This shall be implemented by the construction and operation of a shared distributed infrastructure that aims at making language resources, technology and expertise available to the humanities and social sciences (henceforth abbreviated HSS) research communities at large. See more information about LINDAT/CLARIAH-CZ.
To know more about CLARIN ERIC visit CLARIN-ShortGuide.pdf
If you are interested in more details about our mission, see Mission Statement or the original LINDAT/CLARIN project proposal.
Terms of Service
To achieve our mission statement, we set out some ground rules through the Terms of Service. By accessing or using any kind of data or services provided by the Repository, you agree to abide by the Terms contained in the above mentioned document.
Data in LINDAT/CLARIAH-CZ repository are made available under the licence attached to the resources. In case there is no licence, data is made freely available for access, printing and download for the purposes of non-commercial research or private study. Users must acknowledge in any publication, the Deposited Work using a persistent identifier (see Citing Data), its original author(s)/creator(s), and any publisher where applicable. Full items must not be harvested by robots except transiently for full-text indexing or citation analysis. Full items must not be sold commercially unless explicitly granted by the attached licence without formal permission of the copyright holders.
About UFAL
The Institute of Formal and Applied Linguistics (UFAL) at the Computer Science School, Faculty of Mathematics and Physics, Charles University, Czech Republic was established in 1990 as a continuation of the research and teaching activities carried out by the former Laboratory of Algebraic Linguistics since the early 60s at the Faculty of Philosophy and later at the Faculty of Mathematics and Physics, Charles University in Prague, is a primarily research department working on many topics in the area of Computational Linguistics, and on many research projects both nationally and internationally. However, the Institute of Formal and Applied Linguistics is also a regular department in the sense that it carries a comprehensive teaching program both for the Master's degree (Mgr., or MSc.) as well as for a doctorate (Ph.D.) in Computational Linguistics. Both programs are taught in Czech and English. The Institute is also a member of the double-degree "Master's LCT programme" of the EU. Students also can take advantage of the Erasmus program for typically semester-long stays at partner Universities abroad.
License Agreement and Contracts
At the moment, UFAL distinguishes three types of contracts.
- For every deposit, we enter into a standard contract with the submitter, the so-called "Distribution License Agreement", in which we describe our rights and duties and the submitter acknowledges that they have the right to submit the data and gives us (the repository centre) right to distribute the data on their behalf.
- Everyone who downloads data is bound by the licence assigned to the item - in order to download protected data, one has to be authenticated and needs to electronically sign the licence. A list of available licenses in our repository can be found here.
- For submitters, there is a possibility for setting custom licences to items during the submission workflow.
Intellectual Property Rights
As mentioned above in the section License Agreement and Contracts, we require the depositor of data or tools to sign a Distribution License Agreement, which specifies that they have the right to submit the data and gives us (the repository centre) right to distribute the data on their behalf. This means that depositors are solely responsible for taking care of IPR issues before publishing data or tools by submitting them to us.
Should anyone have a suspicion that any of the datasets or tools in our repository violate Intellectual Property Rights, they should contact us immediately at our Help Desk.
Privacy Policy
Read our Privacy Policy in order to learn how we manage personal data collected by the LINDAT/CLARIAH-CZ repository and services.
Metadata Policy
Deposited content must be accompanied by sufficient metadata describing its content, provenance and formats in order to support its preservation and dissemination. Metadata are freely accessible and are distributed in the public domain (under CC0). However, we reserve the right to be informed about commercial usage of metadata from LINDAT/CLARIAH-CZ repository including a description of your use case at our Help Desk.
Preservation Policy
Read our Preservation Policy to learn more about our commitment to the long-term care of items deposited in the repository.
Why should I submit my data into your repository?
- It is free and safe.
- We respect your license. We encourage Free Data and believe it benefits not only users, but also the data providers. However we accept also more closed data and we can make users sign a license before downloading your data, if that is what you need.
- The data is visible, giving you maximal credit for your work (Google Scholar, VLO, DataCite, OLAC, Data Citation Index, arXive).
- The data is easy to cite. We provide ready-to-use one-click citations in BibTex, RIS, and other popular reference formats. All the citations include permanent links created from persistent identifiers (we use handles for PIDs). These PIDs are future-proof.
- For some data, like text corpora or treebanks, we can provide additional services, like full-text or even tree-query search.
Why should I submit my tools?
- See "Why should I submit my data into your repository?" Everything applies to software tools too.
- You can just link your version control system (svn, git), if it is publicly accessible. You can also link your project page, or demo site.
How to sign up?
We are very glad that you are using our services and that you want to further the experience by obtaining an account. There are basically two paths possible, the preferred and more convenient for both you and us is logging with an institutional account. Below there's an overview of the institutional logins and local logins; both with directions how to obtain the account.
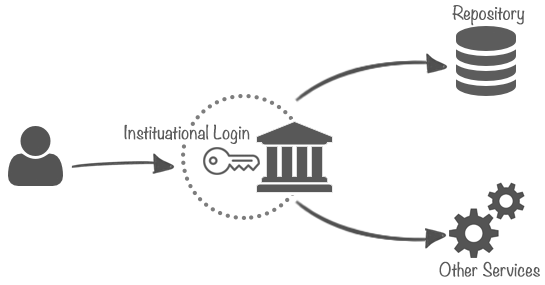
1. Institutional Login
With institutional logins you are de facto logging to a familiar page of your home institution and you are using credentials you already remember. The full procedure is bit more complicated - you initiate the login at our service, you are redirected to your institution and only after successfully logging there you are redirected back. Your institution acts like a sort of a proxy for the multitude of services available in all the CLARIN Centres.
2. Your Institution is not Listed
In case your institution is not listed (but please try searching all the available countries and maybe also using the English name of your institution) the preferred approach is to create an account with CLARIN. After you obtain your account, proceed to login with institution called "Clarin.eu website account".
3. Local Accounts
With a local account you will gain access to only one service, the one you've asked for. When you discover a different service in our infrastructure you'll need to ask again and again. The same goes for services in other EU countries - you'll need to ask and ask and ask. Now it might not seem as that much when you think only one service, but when you think the whole infrastructure it means remembering login/password combination for each of these services. If you are convinced that this is what you need or have some other reason for wanting a local account please contact our Help Desk.
4. From where you can login to our services
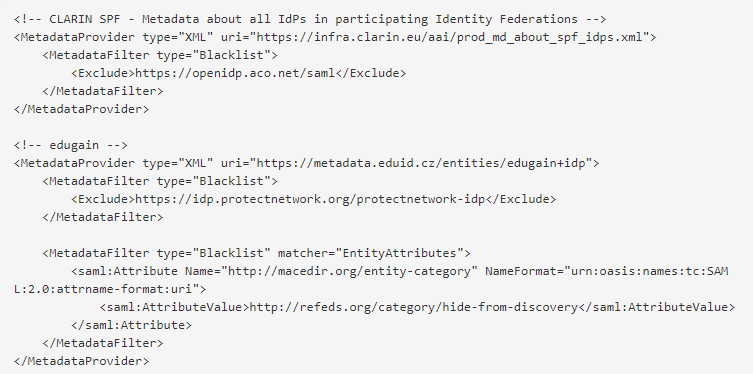
In order to allow access from all over the world, LINDAT/CLARIN service provider is a member of several identity federations including CLARIN SPF and eduGAIN. Unfortunately, some of these federations include identity providers who do not guarantee their users to be real people (e.g., you can trace the account to an email but not to a person). We try to keep our services as open as possible but there are cases (e.g., signing licenses in our repository) where anonymous users are forbidden.
For that reason we choose to exclude users from test IdPs and from IdPs that let you create your accounts online with no further background check.
We are blocking the following IdPs:
- https://openidp.aco.net/saml
- https://idp.protectnetwork.org/protectnetwork-idp
- https://mojeid.cz/saml/idp.xml
- https://umbrellaid.org/idp/shibboleth
- Everyone having entity category http://refeds.org/category/hide-from-discovery
The implementation in shibboleth is illustrated below (snippets from shibbolet2.xml)
5. All logouts are application level only
When you click a logout button in any of our applications you are logged out from that application only; the sp session and idp session are still active. In practice this means when you try to log in again you might not be able to select an idp (the one you've used the last time is remembered) or you might not be asked to enter username/password on your idp page (if you select the same idp, the idp remembers you for some time). You can get more information about why single logout is hard at Shibboleth wiki.
If you need to share your machine (eg. for a presentation) use anonymous/incognito mode of the browser or close the browser (not just a tab); additionally you might want to remove the cookies.
Do I need to create an account to download and/or make a submission?
- You can download data and tools with a license that allows free sharing without any obstacles. Just read the license and download. This applies to all data with Creative Commons and tools with open source licenses.
- To download data and tools that require you to sign a license, you need to log in. To make a submission, you also need to log in. However, if you are from the academic world, you probably don't need any new account.
- Just click "Login" and search for your academic institution. To sign in, you can use any account with an Identity Provider that is a member of EduGAIN federation.
- If you don't have an academic account that works with us, let us know. We will make you a local account.
I see an error logging in
Please let us know through our Help Desk, if you have any trouble logging in.
Occasionally (usually when you are the first one logging in using your home institution) you might see an error stating "The authentication was successful; however, your identity provider did provide neither your email, eppn nor targeted id." This means your home institution did not send us enough data about you to operate our service; the institution is doing so to protect your personal data. We only require an email and we are following Data Protection Code of Conduct, which helps us convince the institution we won't abuse data about you.
If you have an account with multiple providers and you login with different one each time, you might see error stating "Your email is already associated with a different user." Please try to use the same provider each time, if that is not possible, let us know and we'll change the default one.
What submissions do you accept?
We accept any linguistic and/or Natural Language Processing data and tools: corpora, treebanks, lexica, but also trained language models, parsers, taggers, Machine Translation systems, linguistic web services, etc. We do not strictly require you to upload the data itself, although it is always better to do it. Still, you can make a metadata-only record, if required. We also support online license-signing for immediate availability of restricted resources.
When uploading language resources, please try to use one of the recommended formats mentioned in LRT Standards.
Why do you strongly prefer real authors to institutions?
It is not about contact, it is about citations, credit and trust. That is why we have separate metadata fields for authors and for contact person. Contact to a helpdesk is perfect, not acknowledging the authors of a scholarly work is not. We support the direct citation of data (Joint Declaration of Data Citation Principles). That is why we also give them PIDs, create formatted citations, etc. That is the reason we really want proper authors, so that they get citations and other scientists know whose work they rely on.
What is the deposited item lifecycle?
Submitted Item
After you deposit a submission it will be inserted into a pool of submitted items. The item is not publicly available and waits for an editor to approve (or reject) it.
Edited Item
The task of the editor is to verify whether the submission meets our requirements in respect to metadata quality and completeness, bitstream consistency and IPR. The editor can return the submission to the data depositor describing the needed changes. This step is repeated until the editor approves the item. The approved item becomes a published item.
Published Item
A published item obtains a PID (persistent identifier) which should be used for referencing and citing e.g., http://hdl.handle.net/11858/00-097C-0000-0022-F59C-8. The LINDAT repository will ensure that the PID (more precisely, we use http handle proxy of the PID) will be resolved into a working web page (even if the current server infrastructure changes or is moved) describing your resource.
Published items are available through our search interface, browsing mode. Metadata of all items are submitted to search engines and are available through OAI-PMH protocol (several institutes harvest our repository for item's metadata e.g., http://catalog.clarin.eu/vlo/). Bitstreams of public submissions (see Restricted Submissions below) are also available through OAI-ORE protocol.
Deleting and Modifying of Published Item
Anybody can request deletion of published items; however, these will be evaluated on case-by-case basis. Furthermore, we reserve the right to keep the metadata of published submissions available in case there is no specific reason why to delete the metadata. The reason is that it is against the concept of PIDs (persistent identifiers). All PIDs are available through OAI-PMH interface even if only to inform that the item has been deleted.
We allow for minor edits of the submission (e.g., typos) through our Help Desk. These are also evaluated on case-by-case basis. For major changes, the user is requested to submit a new version of that item and we will indicate in the metadata that it is replaced by a newer version.
Restricted Submissions
First of all, all metadata are always publicly available. We support open access submissions; however, we also support restrictive licences for bitstreams which require e-signing before downloading the bitstreams. We keep track of these e-signatures in case there are IPR infringements.
See currently available licenses or contact our Help Desk to add a specific one.
We also support putting embargo on bitstreams which means that the bitstreams become publicly available after specific dates.
What is the actual depositing/archiving procedure?
During the submission of digital language resources to the repository, the data undergo a curation process in order to ensure quality and consistency. We assist you in meeting necessary requirements for sustainable resource archiving. Data have to be provided with metadata in standard formats accepted/adopted in the respective communities, persistent identifiers (PIDs) have to be assigned, IPR issues have to be resolved and clear statements with regard to licensing and possible use of the resources are to be made. The depositor is also required to electronically sign a deposition agreement acknowledging the (s)he is the holder of rights to the data and that (s)he has the right to grant the rights contained in this licence. Once the data is indeed deposited in the repository it is assigned a PID for stable reference.
Only authenticated users can deposit items. If you cannot find your home organisation in the Login dialog list of organisations then register at clarin.eu and authenticate using "clarin.eu website account". In case you cannot use any authentication method above or if you encounter a problem, do not hesitate to contact our Help Desk and we can create a local account for you.
The guide below describes new submissions, if what you plan to submit is a new version of a resource already available in the repository see the new version guide.
Step 1: Login
To start a new submission you have to login first. Click Login under My Account in the right menu panel.
Step 2: Starting a new submission
Now you have a new menu item 'Submissions' under My Account. Click on Submissions to go to the Submissions screen.
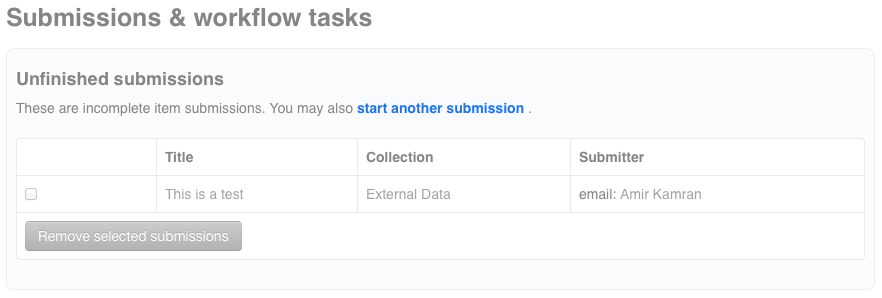
Now you should be on the main Submission and Workflow tasks page where you can view your incomplete/archive submissions. Click on the 'Start another submission' link to start a new Submission.
Step 3: Select type of your submission
You have initiated a new workflow item. In the next few steps you will provide the details about the item and upload content files. First select the type of the resource you are about to submit.
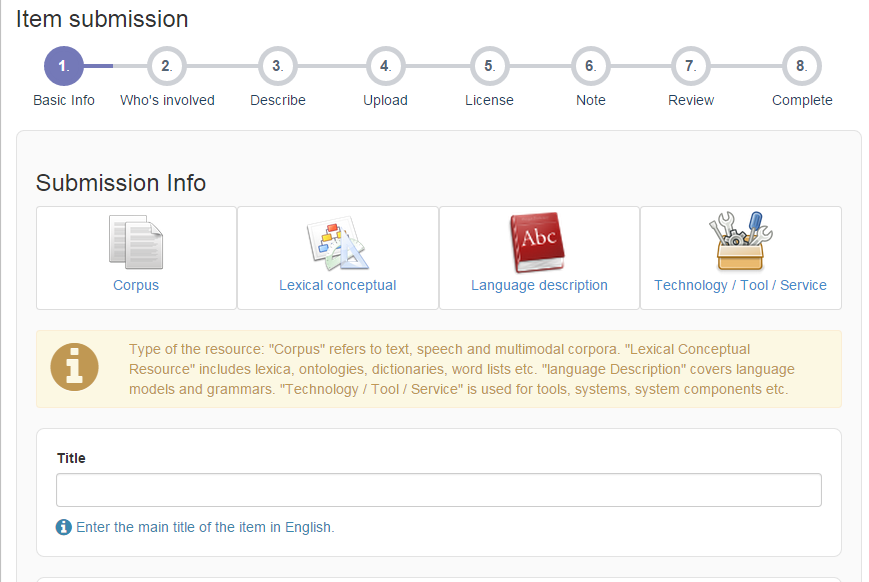
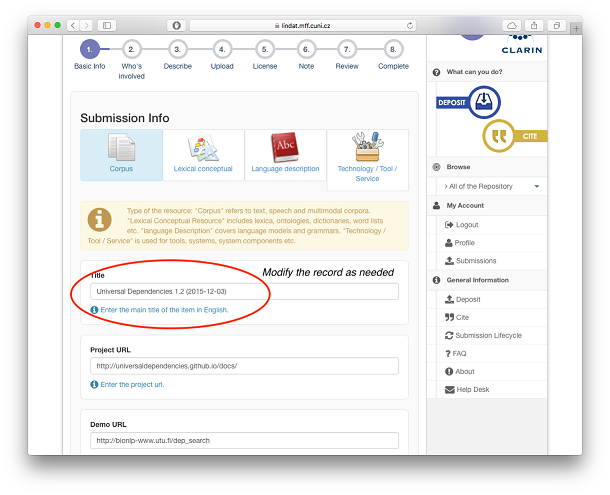
Click on one of the type buttons e.g. Corpus. Proceed with filling the basic information such as the title. Click Next to continue the following step.
Step 4: Describe your item
In the following two steps you will provide more details for your item. First describe the people, organization and projects involved with the item.
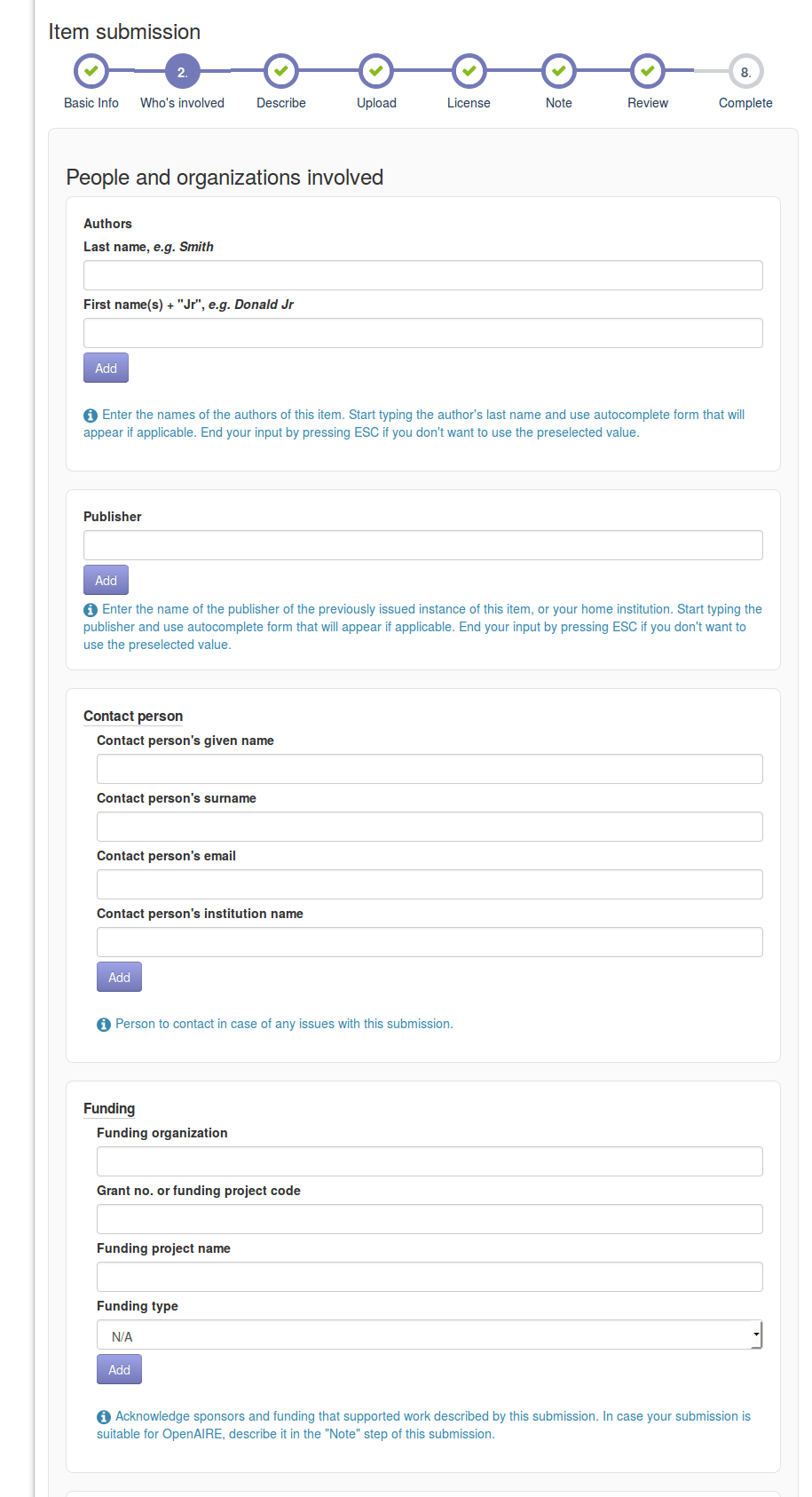
Next add your description, fill the language, etc.
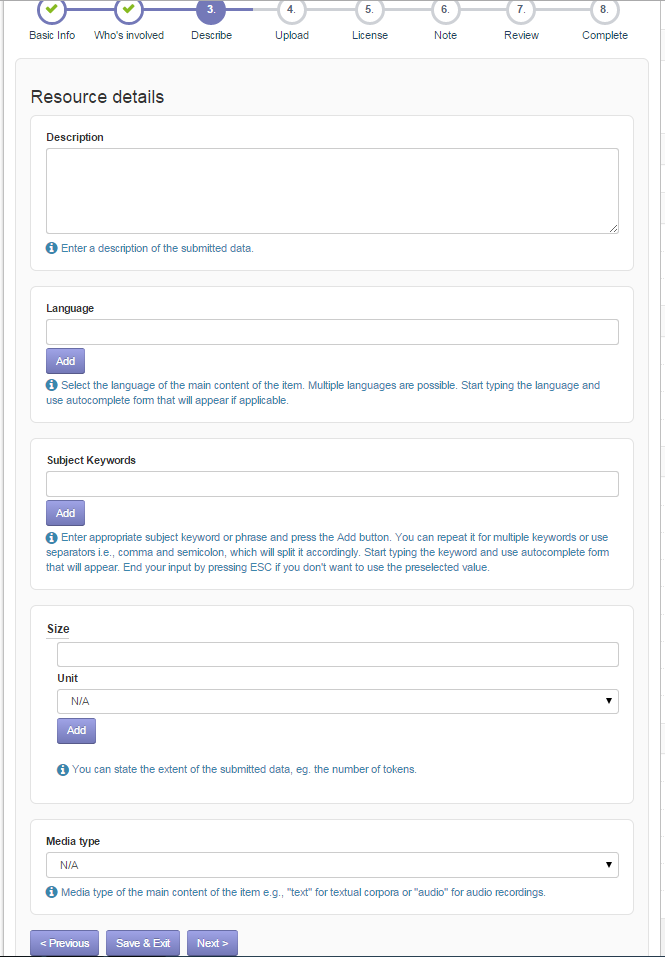
Once you filled the necessary information, click Next to upload the content files.
Step 5: Upload files
In this step you will upload the content files of your submission. If there are no files, you can skip this step by clicking Next. The files can be added by clicking the browse button or you can drag and drop files in the gray area with text 'Drag and Drop file(s) here'.
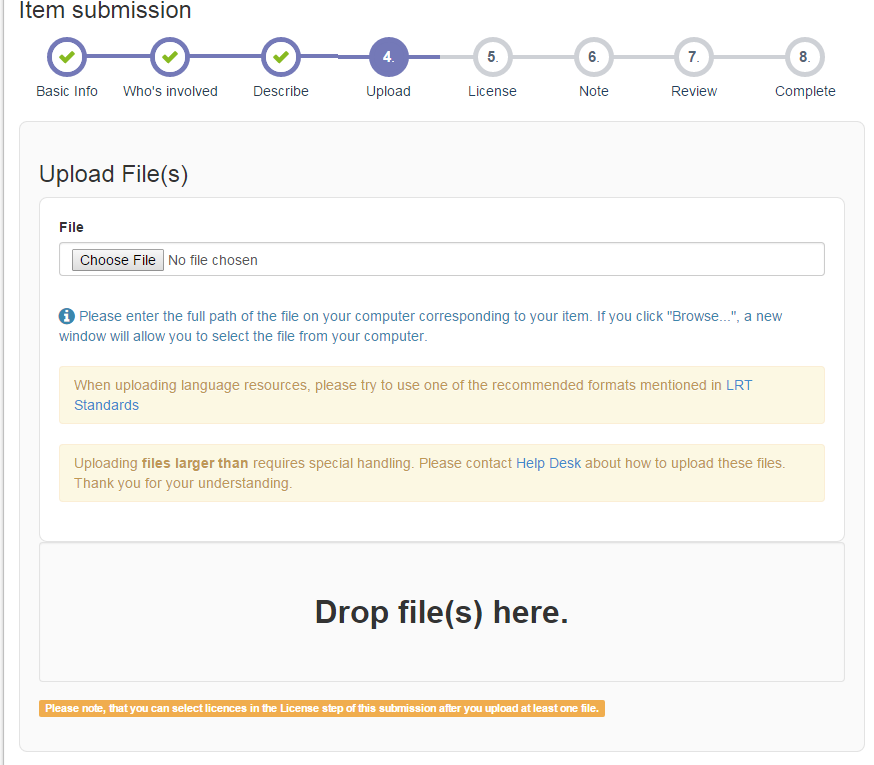
Selecting files will open a dialog box, where you can enter the description of each file. To begin the file upload click 'Start Upload'.
Once the file(s) upload is done, press OK to close the dialog box. You can add more files or delete/modify the already uploaded ones, after you finish press Next to continue with the License selection.
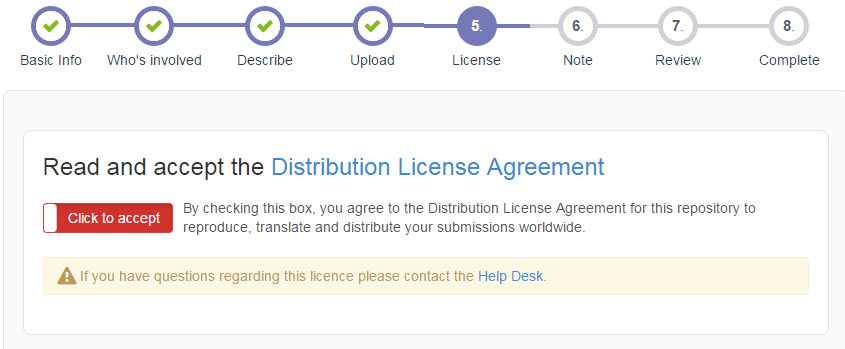
Step 6: Select Licenses
If you uploaded at least one file, you must select a license under which you want your resources to be distributed in this step (data without license is unusable because a user does not know how can he/she use it!). Please read the Distribution agreement carefully and click the red box to indicate your agreement (it will turn green).
Select the appropriate license from the dropdown list, if you already have decided on the license;
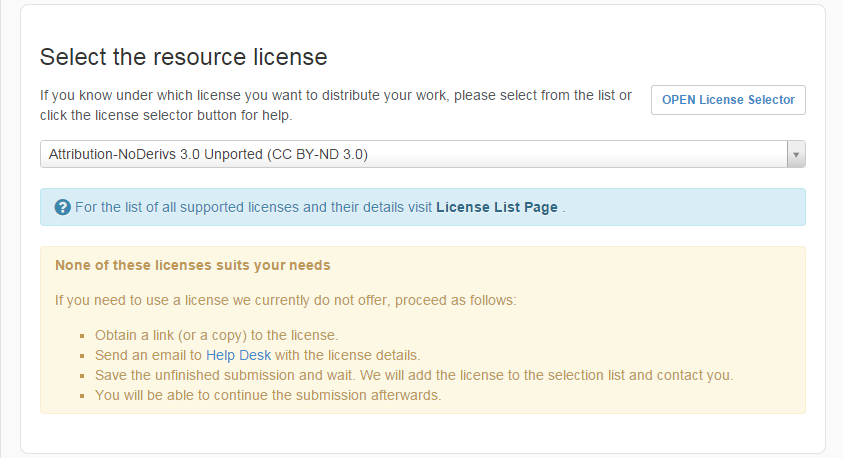
or use the OPEN License Selector, which will help you choose by asking few questions about the submission and your requirements
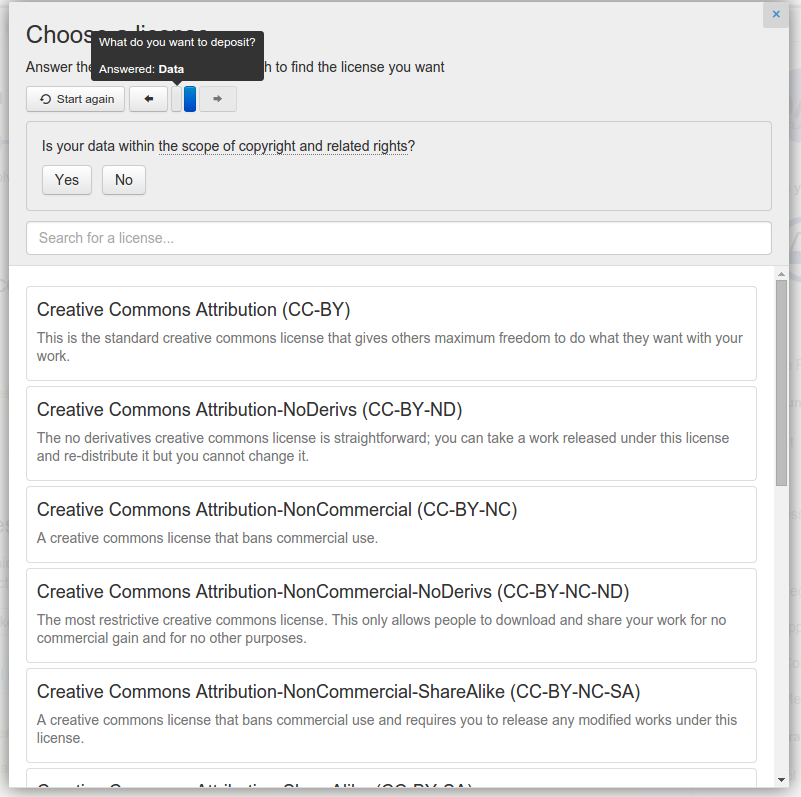
If none of the licenses suits your needs contact our Help Desk.
For datasets that require license signing
While we prefer open data and open source software, we understand it is not always possible. We can ensure that users must authenticate and sign a license in order to download your data (see Restricted Submissions). If you need more information about the users than the fact that they authenticated via a university (or similar), we can ask for some specific attributes similar to standard web forms. This makes sense mostly for data with "no redistribution" clause in their license.
Click Next to continue.
Step 7: Leave a note
You can leave a note for the reviewer in this step.
Step 8: Review your submission
In this step you will review your submission before submitting it. Review page contains a sub-review panel for each of the step you have filled in before. If you want to change any field in a particular step just click Correct one of these and it will take you directly to the particular step page. Once you verify all the detail, submission can be made by clicking Complete Submission or you can click Save & Exit to save the submission for continue working on it later.
Step 9: Submit
Once you click the Complete Submission in the review step, item will be submitted for the reviewing by the editors. Once the editors approve the item it will appear in the repository. In case of any query regarding the submission, editors will contact you for the further detail.
How safe is my data, if I store it with you?
Quite safe, probably much more than in your computer. Our storage plan:
- All the data in the repository have an on-site backup copy.
- There is another off-site copy, so even complete destruction of our building does not destroy your data.
- We check all the copies regularly and should any of them become corrupted we delete it and make a new one.
- We keep at least three copies, one of them off-site, at all times
What is the PID (handle) good for?
It is a special permanent URL. It provides a permanent link that will resolve correctly even if in some distant future the data is moved. Thus it should be used as URL in citations.
New versions/updating submitted data
We do not allow changes in the data after a submission was published. You need to create a new one:
- Log in and go to your existing Submissions. You can only create a new version from your previous submission, not from somebody else's.
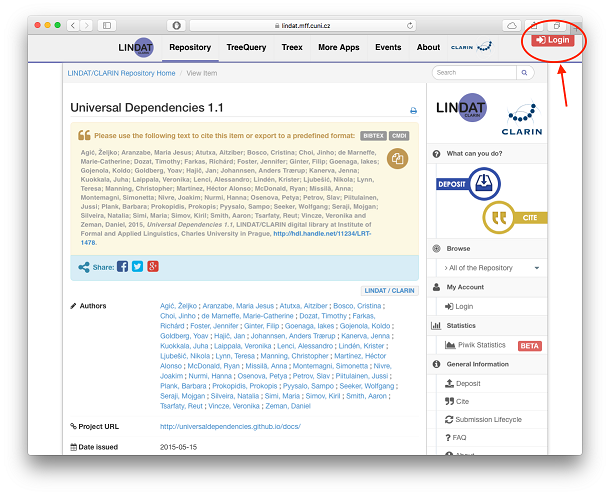
- Scroll down to Archived Submissions, tick the select box of the record you want to create a new version of, and select "Add new version".
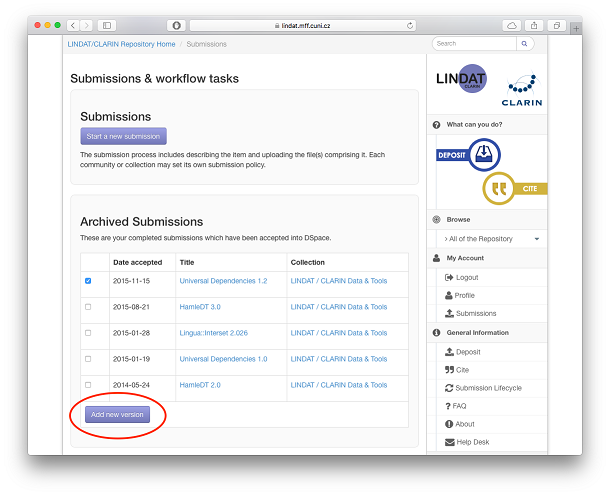
- This creates a cloned record for you, just as if you created a new submission, filled everything in and saved it. Click "Resume".
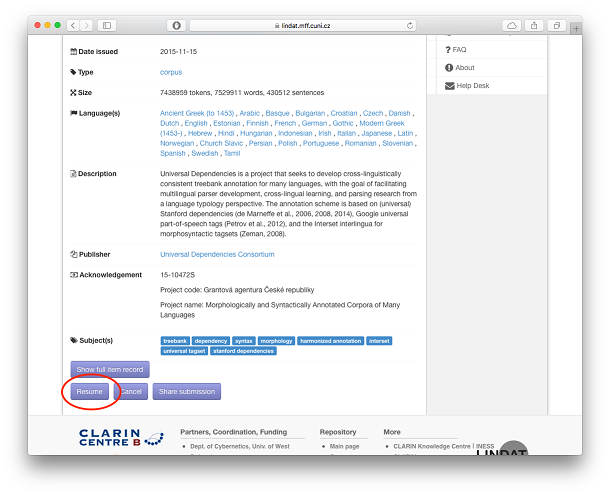
Now you are in the submission workflow. Modify the metadata you want changed (e.g. title), add the bitstreams of this new version and finish the submission as usual.
What if I want/need to update the archived data?
Every change to the resources and metadata should be stored as a new version with a new PID. However if the changes are minimal (e.g., typos or clear mistakes) then contact our Help Desk with the submission PID and the changes which should be made. It is up to the reviewer to decide whether these changes should result in a new version or not.
What if I want to withdraw the resources in the future? Can I delete the data?
Yes, in this case contact our Help Desk with the submission PID and the reason. However, we need to keep a reference that the data was in our repository (because a persistent identifier was issued), so the administrative metadata will be retained indicating that the data itself were removed.
I don't want / cannot make the data publicly available or make them available after a specific date. Would you still archive them for me?
In accordance with the advocacy of the research infrastructures and the general development with respect to Open Access, we strongly encourage the data producers to be as open as possible. However, in other circumstances we will archive your data even if they will not be publicly available. Please, contact our Help Desk prior to completing the submission.
We have started our own repository, can we somehow move records submitted to the LRT collection?
We can create a tombstone page for the moved record and we can add a notice to that page saying the resource is now at a new location. The submission is effectively hidden from search, browse and harvesting (oai-pmh), but the PID still resolves. Thus instead of the actual data, we show a link to the item in your repository. Please contact the Help Desk for more details.
I don't want / cannot make the data publicly available or make them available after a specific date. Would you still archive them for me?
In accordance with the advocacy of the research infrastructures and the general development with respect to Open Access, we strongly encourage the data producers to be as open as possible. However, in other circumstances we will archive your data even if they will not be publicly available. Please, contact our Help Desk prior to completing the submission.
What license should I pick for my data/tool?
We encourage using a free license. A representative selection of free licenses as well as CC licenses (more appropriate for data) is available directly during submission. There is a great OPEN License Selector which can guide you through the selection of appropriate license.
If for some reason you need a different license, contact the Help Desk.
Where can I find more information about supported licenses?
The list of licenses currently supported is here. However, do not hesitate to contact the Help Desk in case you need your specific license. The licenses can be accompanied by various requirements; eg. limiting to logged in users, filling additional details (purpose) etc.
How to cite a submissions?
We strongly feel that data should be cited properly. For that reason we are adopting various policies and creating UI elements to make the citation as easy and as consistent as possible. CLARIN endorses the Data Citation Principles and so do we. We ask Data users to acknowledge and cite data sources properly in all publications and outputs. We already implement the important recommendations of RDA's Data Citation Work Group. See the example of automatic citation text below.
The Handle System provides unique and persistent identifiers of digital objects. We use it to provide your data with a permanent identifier in the form of an URL that will always point to the data, wherever it moves in the future. Thus you can safely use the Handle to point to data for instance in publications. The Handle is part of the RefBox together with other information such as authors, title and publisher.
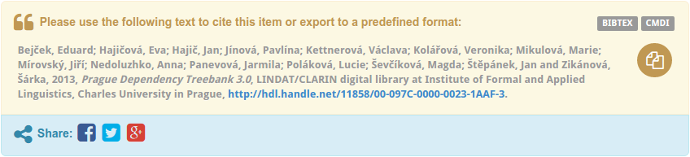
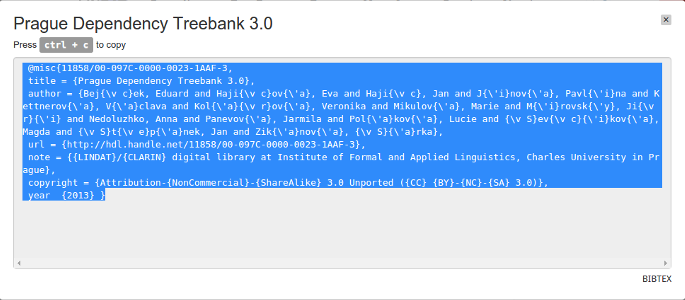
For convenience we've prepared export formats, that can easily be copied and pasted. An item can be exported in BibTeX format. A link to an export is provided in the citation box (see above image). On clicking the link to "BibTeX", formatted BitbTeX entry will be displayed.
How do I get the most of my searches?
In contrast to other search engines this one uses OR as a default operator; see examples below that clarify this. If you are not satisfied with the results of your searches, you might wish to go beyond plain text searches. You may search only in certain fields, use negation, add score (emphasis) to some parts of the query and match more. The search engine is SOLR so use it's syntax if you know it or check it in the documentation.
Examples
- PDT wordnet vs PDT AND wordnet
- The default operator is OR; ie. the first example searches for PDT OR WordNet in all text fields.
- dc.title:P?T && -dc.title:WordNet
- Returns all items having P?T in title - ? stands for any character (eg. PDT) - and not having WordNet in the title
- dc.title:"Czech WordNet"
- Use double quotes (") for exact matches and multiword expressions
- autor:(Bojar && -Tamchyna) && (dc.language.iso:(ces AND eng) OR language:(czech AND english))
- Search for items by one author and not the other; interesting are only items about both czech and english languages.